Steps to Install zeppelin with spark
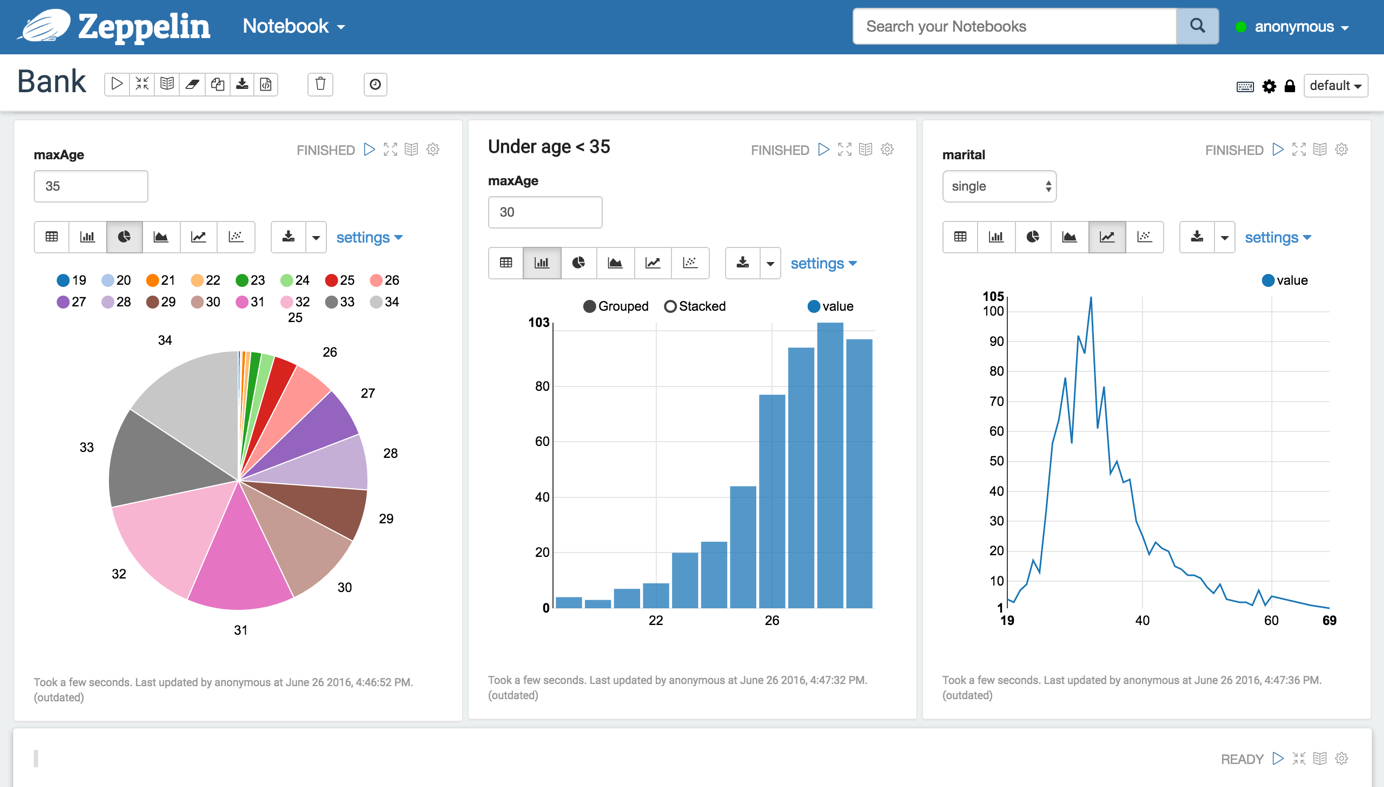
- Data Ingestion, Data Discovery,Data Analytics, Data Visualization &Collaboration we can use zeppelin, below are the steps to install it : 1. Download spark-2.1.0 2.Download zeppein-file from official site 3.Sudo vi .bashrc , and place it in last export JAVA_HOME=/usr/lib/jvm/java-8-oracle export Spark_HOME=/home/ashis/Downloads/spark-2.1.0 5. Source .bashrc 6. cd Downloads/conf 5. Sudo vi zeppelin-env.sh Place the same code here , export JAVA_HOME=/usr/lib/jvm/java-8-oracle export Spark_HOME=/home/ashis/Downloads/spark-2.1.0 6. Sudo vi zeppelin-site.xml Change the port to 8082 from 8080 7. Cd spark-2.1.0 sbin/start-all.sh 8. Cd zeppelin 9. bin/zeppelin-daemon.sh start 10.bin/spark-shell 11. http://localhost:8082/ for zeppelin UI 12. Try Zeppelin tutorial given here : http://localhost:8082/#/ or if its not working you can follow below link https://gist...

